

L’Intelligence Artificielle est un domaine scientifique tentaculaire. Il est difficile d’appréhender globalement le sujet sans catégoriser.
Ce deuxième article de la série a pour objectif de présenter les grands concepts de l’I.A. de manière organisée.
Schéma d’ensemble

Pour faciliter l’exploration du domaine, il est important de structurer les informations. Je vous propose de le faire sous 3 angles différents :
- Définitions et méta-concepts : comment définir l’intelligence artificielle ? Comment la représenter ? Sur quels concepts ou méta-concepts elle s’appuie ?
- Théories scientifiques et algorithmes : les grands courants de pensée et les grandes familles d’algorithmes ;
- Techniques et mise en œuvre : les logiciels et les matériels utilisés.
Les prochains articles feront désormais référence à cette organisation. Les schémas qui suivent vont décrire plus précisément chaque angle de vue. Cependant, ils ne sont pas exhaustifs. Ils posent les différents thèmes sans descendre dans le détail (sinon les illustrations seraient illisibles).
Angle 1 : Définitions et méta-concepts
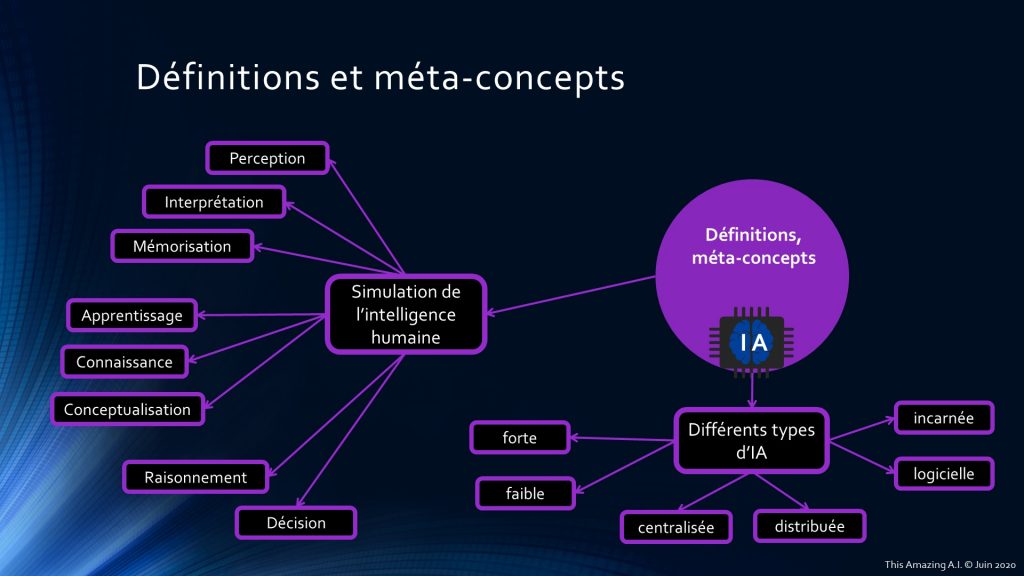
Pour bien poser les bases de l’intelligence artificielle, il faut repartir de la définition. Avant tout, nous appelons communément IA ce qui a trait à la simulation de l’intelligence humaine et les neurosciences sont au cœur de cette quête de compréhension de ces processus internes. Quels sont les mécanismes mis en avant ? Nous pouvons les classer en 3 blocs principaux :
- Perception : en premier lieu, la perception des informations dans l’environnement par des dispositifs adaptés en fonction des signaux que l’on souhaite capter. Dans un second temps, le processus d’interprétation des signaux. Et enfin, leur mémorisation de manière adéquate ;
- Apprentissage : le processus d’apprentissage s’appuie sur une base de connaissances (issues de la première étape de perception) et permet la conceptualisation ou la généralisation de nouvelles informations, modèles ou règles ;
- Décision : fort de toutes ces nouvelles connaissances et ces nouveaux concepts, nous pouvons raisonner sur les meilleures décisions à prendre pour agir au mieux de nos intérêts et ainsi atteindre nos objectifs.
De plus, ces processus ne sont pas autonomes et interagissent constamment. En effet, ce que nous observons va nous permettre de créer de nouvelles connaissances, d’élaborer des raisonnements, prendre des décisions qui vont à nouveau influencer notre manière d’observer puis modifier nos modes de pensées. C’est une boucle de rétroaction.
Mais il y a encore de nombreux mystères à éclaircir avant de pouvoir mettre en œuvre totalement et conjointement ces processus. Nos connaissances sont encore parcellaires.
Remarque : je ne fais pas état des capacités de communication et tout ce que cela induit : construction d’un langage, sémantique, protocoles d’échange, etc. Mais il faut garder en mémoire que c’est un point important dans le cadre d’une interface de conversation homme / machine ou machine / machine.
Nous distinguons également plusieurs types d’IA.
- IA faible ou IA forte : l’IA forte (ou IA générale) représente souvent le Graal pour certains scientifiques ou le début de la fin pour d’autres. Elle serait l’équivalent de l’Homme (peut-être même plus), dotée d’une capacité de réflexion autonome, d’une conscience d’elle-même. En résumé, elle posséderait tous les attributs d’un être vivant et pensant. Mais ce n’est encore que de la science-fiction. L’IA faible est celle que nous connaissons aujourd’hui et nous pouvons la considérer plus comme un outil intelligent ;
- Centralisée ou distribuée : une IA centralisée n’est localisée qu’à un seul endroit (en l’occurrence une unique machine). En revanche, une IA distribuée est répartie sur un ensemble de machine (serveurs) et fonctionne un peu comme un essaim d’abeilles, chaque partie faisant ce qu’elle est censée faire de manière plus ou moins autonome pour servir un tout. Il faut considérer également des problématiques de coopération, collaboration et synchronisation ;
- Logicielle ou incarnée : dans ce cas précis, j’ai fait le choix de distinguer une IA totalement logicielle, d’une IA « incarnée », c’est-à-dire plus proche de la robotique. Cette dernière contient évidemment une partie logicielle mais également du matériel comme des capteurs physiques (senseurs et/ou actionneurs).
Ces trois blocs ne s’excluent pas mutuellement. En effet, nous pouvons imaginer une IA faible, logicielle et centralisée, comme par exemple, un système expert pour le choix d’un prêt bancaire ou un programme produisant un modèle d’apprentissage de l’âge des arbres en fonction de leur taille ; ou une IA faible, distribuée et incarnée, comme une flotte de drones de reconnaissance agissant ensemble pour établir la topographie d’un lieu.
Angle 2 : Théories scientifiques et algorithmes
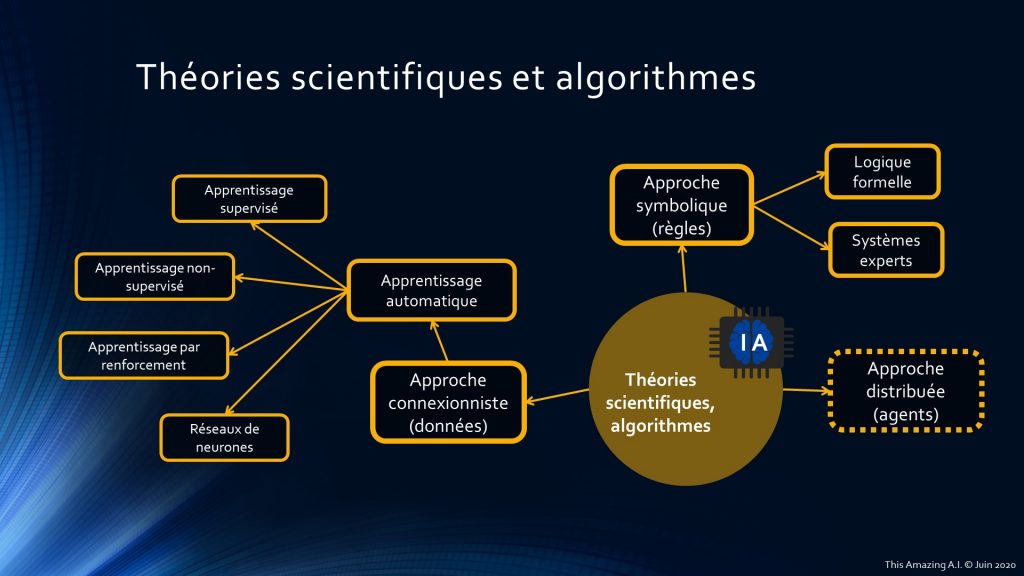
Chaque concept introduit précédemment trouve sa projection ici, le but étant de le traduire en algorithmes. Il existe principalement 3 approches :
- Approche symbolique basée sur des règles, connaissances, prédicats, etc. Nous y retrouvons la logique formelle qui en est à l’origine et nous pouvons citer les systèmes experts comme application ;
- Approche connexionniste basée sur les données qui a beaucoup de succès en ce moment (grâce aux progrès matériels essentiellement). C’est ce que nous appelons aussi apprentissage automatique (ou Machine Learning). Il peut se découper en 4 sous-catégories :
- Apprentissage supervisé : avec des données labellisées et utilisation d’algorithmes de type régression linéaire ou polynomiale ou encore de catégorisation (classification en anglais) : arbres de décision (decision tree), Naive Bayes, SVM, etc ;
- Apprentissage non-supervisé : avec des données non-labellisées. Par exemple, trouver des corrélations en utilisant des algorithmes de classement automatique (clustering en anglais) de type K-Means, DBSCAN ou des recherches de motifs (pattern search), etc ;
- Apprentissage par renforcement : entrainement d’un modèle où l’on maximise la fonction de décision (avec une récompense) étant donné un état de l’environnement (algorithmes génétiques, Q-Learning, Deep Q-Network, etc) ;
- Apprentissage profond (réseaux de neurones) : appelé aussi Deep Learning, avec des réseaux à convolution (CNN Convolutional Neural Networks), récurrents (RNN Recurrent Neural Networks), des GAN (Generative Adversarial Networks), des auto-encodeurs, etc ;
- Approche distribuée : il faut raisonner sous forme d’agents plus ou moins intelligents qui vont effectuer tout ou partie d’un travail pour remplir des objectifs (individuels ou collectifs). J’ai volontairement mis ce sujet un peu à part car nous pouvons y mélanger les approches. Par exemple, avoir un agent intelligent avec des comportements basiques s’appuyant sur des règles mais dont les perceptions (observations) vont servir à apprendre de nouvelles règles et/ou entraîner des modèles de type connexionniste (comme un apprentissage par renforcement).
Remarque : l’objectif est de donner un aperçu des théories et des techniques, pas de faire un cours magistral sur le sujet. Je pourrais approfondir les notions progressivement.
Enfin, nous pouvons citer des approches hybrides ou d’IA floue mélangeant les approches pour en tirer le meilleur en fonction du contexte. En effet, il est important de comprendre que ces approches ne s’opposent pas du tout et peuvent se compléter.
Angle 3 : Techniques et mise en œuvre
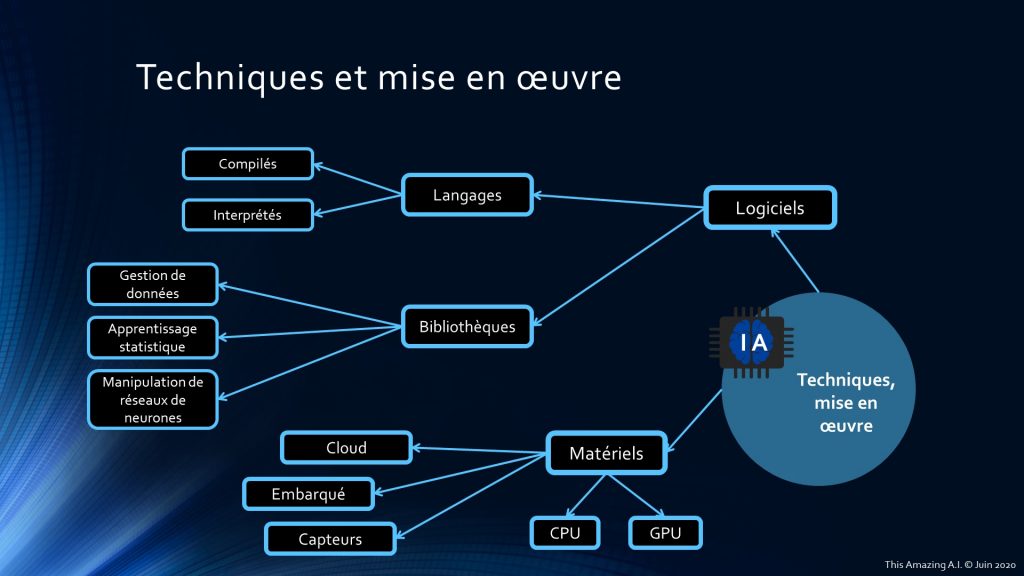
Nous avons vu les grands concepts et les méta-concepts. Ils se traduisent en théories scientifiques et algorithmiques. Mais pour pouvoir les programmer et les exécuter, il faut s’appuyer sur des logiciels et des matériels. J’ai donc décidé de les catégoriser en 2 groupes :
- Logiciels :
- Langages : compilés (par exemple C++) ou interprétés (par exemple Python) ;
- Bibliothèques : de gestion de données, d’apprentissage statistique, de manipulation de réseaux de neurones (par exemple TensorFlow, Keras) ;
- Matériels :
- Types de processeur : CPU, GPU (et bientôt quantique) ;
- Capteurs de détection et perception (visuelle, auditive, haptiques, etc) ;
- Lieu d’exécution : sur des serveurs, en Cloud, dans des Data Centers ou encore embarqués (par exemple, en robotique avec le Jetson de Nvidia).
Remarque : Il ne s’agit pas d’un inventaire exhaustif mais seulement d’un choix personnel d’organisation. Je ne dresse pas non plus la liste de toutes les plateformes logicielles existantes. Cela pourra être fait au fur et à mesure des publications.
Le dernier article de cette série va proposer quelques perspectives potentielles et lister quelques nouvelles considérations liées au domaine.
Vous pouvez retrouver l’intégralité de cette présentation dans la section Infographies.